Meta AI recently published a new framework (AV-HuBERT) to improve automatic speech recognition thanks to lips monitoring, de facto combining Speech with Vision, two of the traditional areas of Artificial Intelligence. Incorporating data on both visual lip movement and spoken language, AV-HuBERT aims at bringing artificial assistants closer to human-level speech perception (see META AI blog post). Anyone who has ever dealt with a voice assistant would be pleased with any improvement in this user experience. In this graph, you can see the lower Word Error Rate of this model by the same amount of training data (on the right), or the still very low error rate using a fraction of training data (in the middle).

Similarly, machine interpreting (also known as automatic spoken translation) could potentially profit from the integration of computer vision with natural language processing. The recognition of emotional facial expressions, for example, is a central aspect for an effective interpersonal communication. And Machine Learning is quite good at classifying emotions and sentiments. This applies to emotion detection both in the acustic features of the voice, using pitch, speed, pauses, and in facial expression, evaluating the movement of eyebrows, lips, and so forth.
A lot of research at the intersection between Computer Science, Ethics, and Psychology is going on in this area (see this paper by Zhenjie Song for an overview). In speech translation first projects are already trying to triangulate speech and visual inputs to compensate for missing source context (see this paper by Lucia Specia et al.). Notwithstanding many unsolved challenges in this domain, such as the cultural determinism of emotions, ethical questions, such as racial and gender bias in data, as well as the possible misuse of the underlying technology (see Harari’s interview about Hacking Humans), the positive impact that it may have on the domain of speech translation should not be underestimated. Provided, of course, that the technology keeps its promise.
Similar to machine translation, machine interpretation still suffers from being unable to process anything more than the mere surface of the language, i.e. the words. While the codification of meaning and intention in words is obviously important, the limitation of today’s translation systems to this level of data is relevant if we accept the rationale that in human communication meaning arises not just from words, but from shared knowledge, prosody, gestures, even the unsaid, to name just a few.
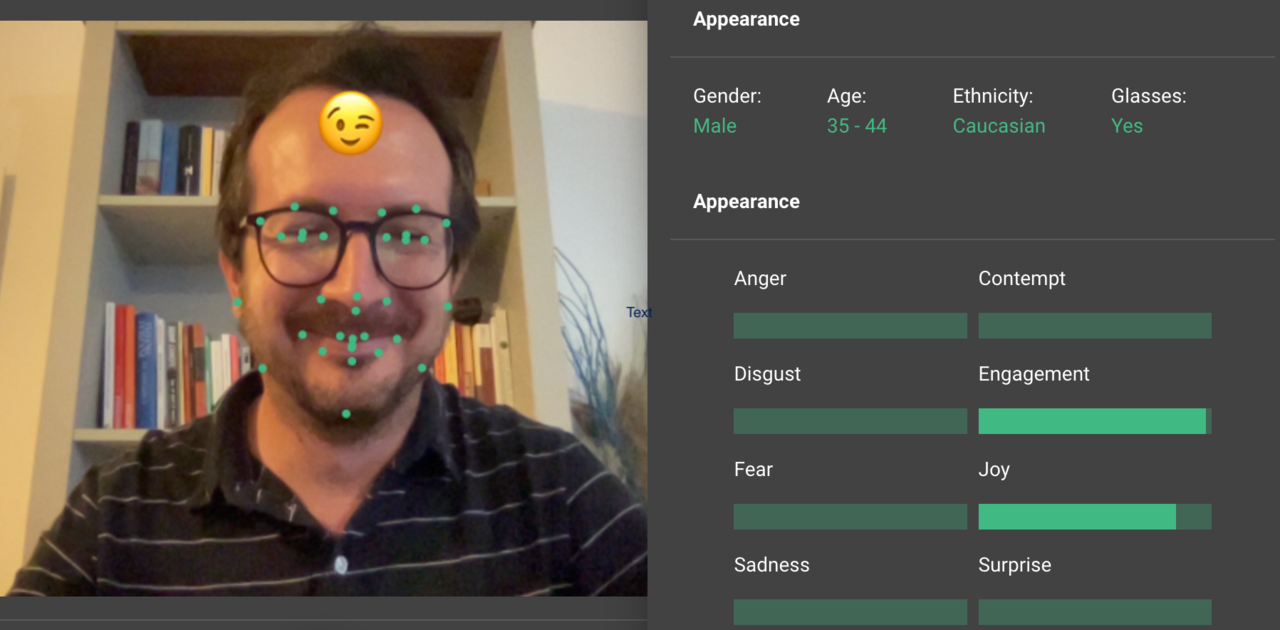
Adding contextual knowledge about the world and the specific situation in which the communication is happening (semantic knowledge), and specific data points about the speaker, for example, the emotions expressed by the tone of her voice or, as in the case of the screenshot below, by her facial expression, will bring new contextual information to the translation process. This will enable us to augment the shallow translation process that we are doing now, allowing for a translation that is more ’embedded in the real world’. This is the promise.

There is still a long way to go to a richer translation experience and the number of uncertainties is very high. Matching the competence of a skilled human interpreter remains out of the scope of this type of research. However, chances are that improved quality of such systems will allow – at some point in the future – to foster accessibility and inclusion in our globalized and multilanguage world.
1 thought on “Facial emotion recognition may improve automatic speech translation”