
Automated spoken language translation is advancing quickly. This technology has various applications and use cases, each with subtle differences that can overwhelm many people. Despite this, understanding these nuances is crucial. That’s why I spent a significant part of my recent workshop “The State of Machine Interpretation” at GALA defining what Machine Interpreting is. In my opinion, this understanding is essential because the technology, expectations, and quality vary greatly depending on these subtleties.
The automated translation of spoken language from one language to another, either in written or other oral form, goes by several names. In computer science, the term Speech Translation is commonly used. In this domain, Speech-to-Speech Translation specifically refers to the translation of spoken content from one language into spoken content in a different language. This is in contrast to speech-to-text translation which is generally used to produce subtitles, reports, or written translation of spoken content.
An important distinction that needs to be made is about the time in which the translation is carried out. Speech-to-speech translation can be conducted offline or live. It is offline when it is applied to prerecorded audio or video files. This is common for example in the production of dubbed or voiceover content for mediums such as video games, presentations, and documentaries. In an offline scenario, the translation can be edited by humans prior to publication. Editing can consist in improving the translation itself, or to adapt the voices, their emotional content, etc. to the video. The translated audio can be applied to the video with zero latency, pushing this limit even further by adapting the mouth movements of the speaker to the translation (or vice-versa) and create almost perfect synchronicity (see the AI dubbed version of Argentina’s president at Davos).

Speech-to-speech translation can also function live, or in real-time or streaming mode, to use more technical terminology. Machine Interpreting specifically refers to this mode of translation. It also known by the names Machine Interpretation or AI Interpretation. While this terms are primarily used in Translation Studies, they have gradually permeated common language as this technology transitions from research to real-world application.
Machine interpreting is distinct from all other forms of speech-to-speech translation in its emphasis on immediacy, meaning the translated message is delivered instantaneously and cannot be revised post-delivery, mirroring the dynamics of human interpretation. Like other forms of speech translation, but even more so, machine interpreting may require nuanced intervention in the translation process. This can involve adaptations, omissions, reformulations, or other modifications to ensure communication is effectively tailored for specific contexts.
Machine Interpreting can be either consecutive, where the machine processes and translates an entire oral segment (such as a sentence or longer passage) after it is spoken1, or simultaneous, where the translation is generated incrementally as the original speech is being delivered, i.e. based on partial input2. This difference is very important.
From a technological perspective, consecutive machine interpreting has many similarities to offline speech-to-speech translation. The translation is done knowing the entire text that needs to be translated. And this is a huge advantage for the machine (as it is for humans). It differs however in terms of the necessity to perform the translation very fast because it needs to be used immediately. But this is only a technical aspect, not a linguistic one. From a communicative/user perspective, the difference is the fact that there is no possibility to edit the result: the users will consume the raw translation.
On the other side, simultaneous machine interpreting is really the most intricate and challenging form of machine speech-to-speech translation, as it necessitates translating an ongoing stream of speech incrementally, without pausing the original speech. This also means that the translation is done, by definition, lacking full context — for instance, not knowing what the speaker will say next. Achieving (near) simultaneity demands that speech be broken down into significant, coherent segments in real time, enabling prompt and coherent translation. Moreover, the system must construct a logical and articulate flow of text in the target language, starting from partial segments of speech. This task is far from straightforward.
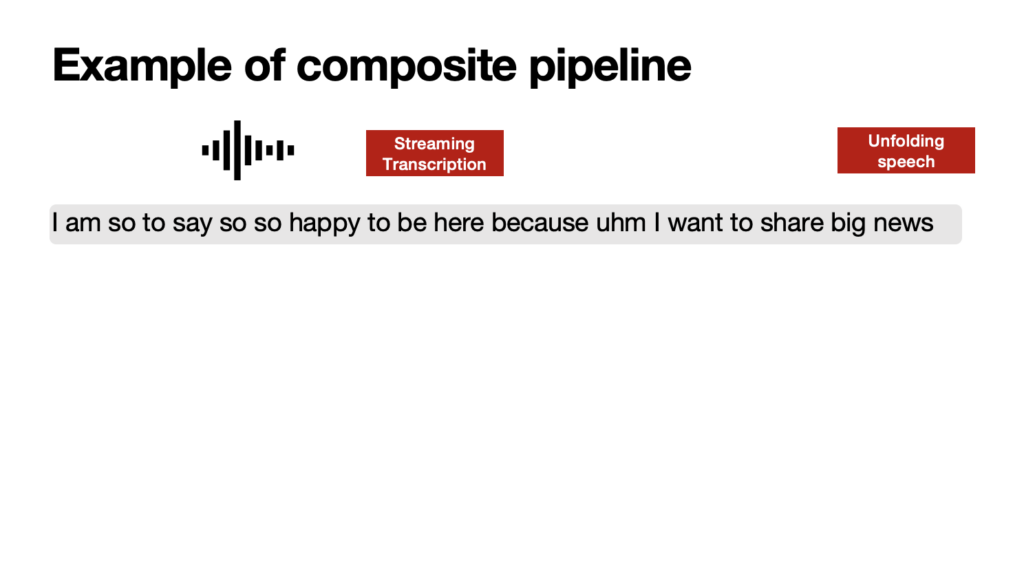
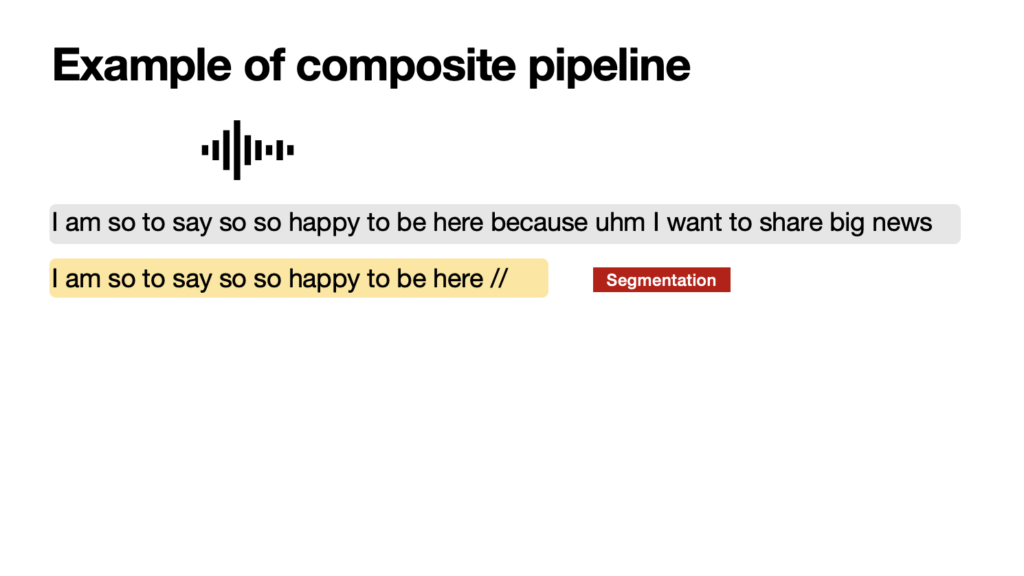



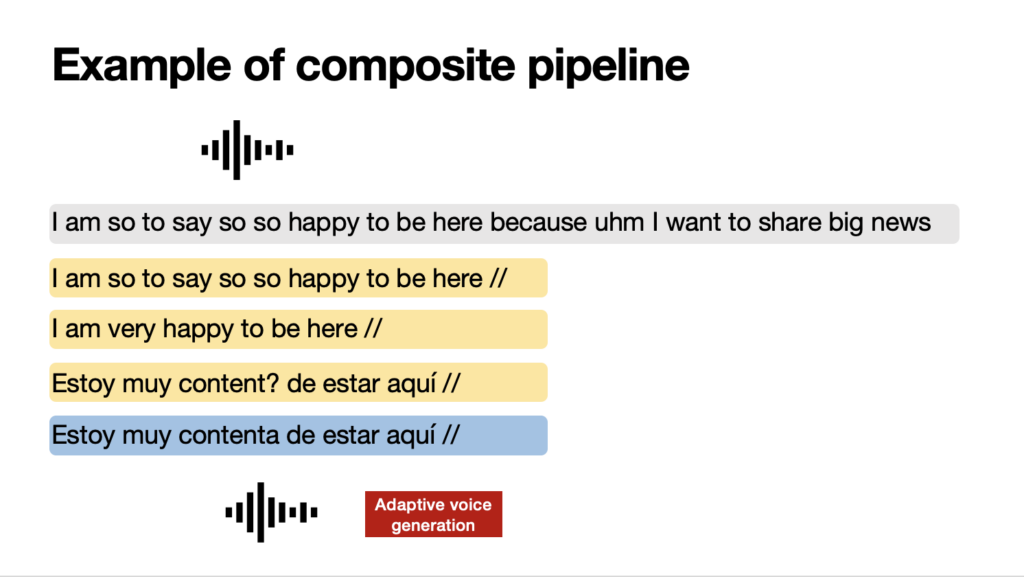
The aim of a simultaneous interpreting system is to balance translation accuracy with latency. Latency, known as the ear-voice span in Interpreting Studies, is the time lag, measured in seconds, between the utterance of a word or concept and its translation by the system into the target language. The challenge lies in managing latency: reducing it means the system has less context for the translation, which can negatively impact accuracy. Conversely, allowing more latency will enhance the translation quality but will detract from the translation experience. To segment speech, methods vary from recognizing pauses in the speaker’s delivery and using fixed word counts to implementing dynamic strategies that analyze the syntax and semantics of the incoming speech in real time.
The specific terminology used is relatively secondary. Whether one refers to the technology or its application as speech-to-speech translation or machine interpreting isn’t significantly crucial. What matters most is having a clear understanding of the subtleties involved, both in terms of the technology itself and its application. As one can assume, if we want to stick to my terminology, one thing is clear: Machine Interpreting is the most particular and challenging form of speech-to-speech translation. Because of its features, especially in live and simultaneous settings, the quality and synchronicity to the original will be slightly lower compared to offline translation, but research and applications are making big strides also in these aspects.
- A freely accessible tool for consecutive AI interpretation can be found here: https://www.machine-interpreting.com/ (disclaimer: I am the creator of this tool) ↩︎
- A business tool for simultaneous AI interpretation can be found here: https://kudoway.com/solutions/kudo-ai-speech-translator/ (disclaimer: I designed this speech translation tool) ↩︎
5 thoughts on “Defining Machine Interpreting”